von Ramon Forster • Juli 18, 2018
Es spricht vieles dafür, dass eine der mühsamsten Aufgaben und grössten Belastungen inzwischen von künstlicher Intelligenz (KI) übernommen werden kann: das Taggen von digitalem Content. Trotz des grossen Potenzials der KI beim Auto-Tagging von Content, wird trotz grosser Versprechen seitens der Hersteller zunächst eine solide Informationsarchitektur gebraucht.
Dieser Artikel soll als Entscheidungshilfe bei der Verwendung von KI-Technologien für das Auto-Tagging von digitalem Content dienen und gibt Aufschluss über wichtige Einschränkungen und Vorbehalte.
Künstliche Intelligenz: Erwartung vs. Wirklichkeit

Sollen nur Urlaubs- und Archivbilder verwaltet werden, kann Auto-Tagging beim Auffinden der gesuchten Bilder helfen. Hierfür reicht ein grosser Speicherplatz, z.B. bei Google Drive oder Microsoft OneDrive möglicherweise schon aus. Schliesslich ist bei diesen Anbietern die KI bereits eingebaut — und das fast kostenlos.
Bei sehr unterschiedlichen Content-Typen (Bilder, Videos, anderer Produkt-Content, Bauteile, Events oder Schlüsselpersonen) funktioniert das Auto-Tagging in einigen Bereichen recht gut, für andere ist es dagegen eher nutzlos, weil ein bestimmtes Produkt XYZ nicht besser gefunden wird als vorher. Bei der Suche nach “Personen” will man nicht tausende von Bildern mit Personen durchscrollen, um erst ganz am Ende die Vorstandsmitglieder zu finden.
Dennoch kann das Auto-Tagging sehr hilfreich sein — in Zukunft sogar noch mehr. Das muss jedoch sorgfältig vorbereitet werden. Schliesslich ist das Auto-Tagging selbst nicht das Ziel. Es automatisiert nur bestimmte Teile eines grösseren Prozesses. Das Ergebnis eines solchen Prozesses kann dabei nur so gut sein wie die verwendete Informationsarchitektur.
Die sorgfältige Definition der Informationsarchitektur und des Content-Management-Prozesses zahlen sich später auf vielfältige Weise aus, wie ich gleich erläutern werde.
Wie Auto-tagging funktioniert
Künstliche Intelligenz untersucht ein Bild üblicherweise auf Vektoren, Formen, Farben und andere visuelle Merkmale. Diese Muster werden dann mit einer Referenzbibliothek verglichen, um die Namen der identifizierten Objekte in Textform zu ermitteln. Für jeden Treffer wird ein Tag zurückgegeben. Dieses ist mit einem Wert für die Zuverlässigkeit versehen, der angibt, wie “sicher” sich der Algorithmus ist, einen korrekten Treffer gefunden zu haben (“confidentiality score”).
Das Wissen, dass etwas ein Computer mit einem Apfelsymbol ist, hilft beispielsweise bei der Unterscheidung zwischen der Marke Apple und einem tatsächlichen Apfel (Frucht).
Hoch entwickelte Algorithmen können identifizierte Objekte ausserdem zueinander in Beziehung setzen und die zurück gegebenen Ergebnisse damit weiter optimieren: Das Wissen, dass etwas ein Computer mit einem Apfelsymbol ist, hilft beispielsweise bei der Unterscheidung zwischen der Marke Apple und einem tatsächlichen Apfel (Frucht).
KI-Algorithmen können allgemeine Inhalte wie Früchte, Berge, Personen, etc. bereits recht gut erkennen. Aber auch die Unterscheidung von Details wird ständig verbessert, so dass beispielsweise ein Granny Smith-Apfel, der Mount Everest oder eine berühmte Person des öffentlichen Lebens erkannt werden können.
Ein Modell kann ausserdem so trainiert werden, dass Anbieter von KI zur Bilderkennung wissen, dass es sich bei einer Abbildung um Bauteil X der Maschine Z handelt. Allerdings sind sie darin noch nicht besonders gut und die meisten Algorithmen können noch nicht richtig erkennen, welche Teile eines Bildes tatsächlich relevant sind, da ihnen der historische oder ein erweiterter Situationskontext fehlt.
Informationsarchitektur als notwendige Basis
Am Anfang sollte grundsätzlich der Aufbau einer passenden Informationsarchitektur stehen — unabhängig davon, ob die KI im Digital Asset Management, bzw. als Teil einer Content Management-Strategie eingesetzt werden soll, oder ob man abwarten möchte, bis diese Technologien weiter verbessert werden.
Ein guter Startpunkt besteht in der Beantwortung der folgenden Fragen:
- Welche Arten von Content sollen verwaltet werden?
Wenn man beim Content nur zwischen “Bildern, Videos und PDFs” unterscheidet, klingt das womöglich trivial. Tatsächlich sollte man versuchen, die Arten des Contents zu definieren, der in Form von Bildern und anderen Dateitypen erfasst wird: Produkt-Content, Event-Content, Mitarbeiter-Content, allgemeiner Archiv-Content, etc.

Sobald man sich darüber klar ist, sollten zumindest die folgenden Fragen für jeden zuvor definierten Content-Typ beantwortet werden:
- Welche Metadaten müssen mindestens erfasst werden?
- Welche vordefinierten Taxonomien sollen für die verschiedenen Metadaten-Typen verwendet werden?
- Wie genau müssen die verschiedenen Metadaten getaggt werden?
- Ist es erlaubt, den Cloud-Dienst eines Drittanbieters für das Auto-Tagging zu verwenden?
- Welche weiteren Ressourcen (Menschen, Systeme) können für das Tagging herangezogen werden?
Diese Fragenliste erhebt keinen Anspruch auf Vollständigkeit und geht nicht auf jedes Detail ein. Dennoch kann sie als Startpunkt dienen. (Eventuell besteht die Möglichkeit, sich über das DAM Guru Program von einem Digital Asset Management- oder Content Management-Experten helfen zu lassen.)
Die Beantwortung der oben stehenden Fragen ist entscheidend, um ein besseres Verständnis der weiter unten genauer behandelten Implikationen zu erhalten.
Auto-Tagging trifft auf Taxonomien
Auto-Tagging-Dienste geben immer nur einfache “Tags” (Textstrings) zurück. Meistens speichern Content-Systeme diese Informationen in einem Freitext-Feld, was für einfache allgemeine Suchabfragen meistens ausreicht, jedoch nicht, wenn ganz bestimmter Content basierend auf eigenen speziellen Vokabularien gefunden werden soll.
Soll die Auffindbarkeit und die Benutzerführung während einer Suche in grossen Content-Mengen verbessert werden, kommt man um die Verwendung von Metadaten-Filtern (wie sie in fast allen e-Shops zum Einsatz kommen) nicht herum. Diese Filter oder “Facetten” werden nach Content-Typ (z.B. Produkt- oder Archivbild), Medientyp (Bild oder Video) und nach Konzeptkategorien (z.B. Geographie oder Menschen) unterteilt.
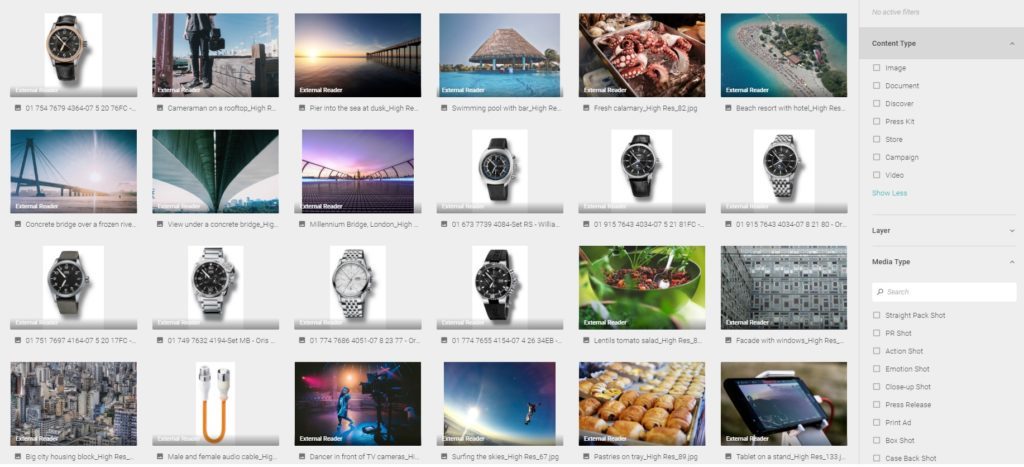
Um mithilfe von Filtern einen Vorteil bei der Benutzerführung zu erlangen, müssen die von einem Auto-Tagging-Dienst zurückgegebenen Tags mit der eigenen Taxonomie abgeglichen werden. Gibt der Auto-Tagging-Dienst beispielsweise das Tag “Frauen” zurück, so muss dieses ggf. auf den internen und möglicherweise weiter gefassten Begriff “Personen” abgebildet werden.
Noch besser ist es, wenn das verwendete Content System mehrdimensionale Metadaten und semantische Beziehungen unterstützt. Dann kann das Tag “Personen” mit allen möglichen Zusatzinformationen angereichert werden und beispielsweise auf das “Frauen”-Tag verweisen, dass wiederum auf “Mädchen”, “weiblich”, “Mutter” und andere mögliche Synonyme verlinkt.
Mehrdimensionale Metadaten helfen besonders bei der Arbeit Produktinformationen. Wird ein Product Information Management (PIM)- oder Enterprise Resource Planning (ERP)-System verwendet, ist der Einsatz von KI-Voodoo nicht einmal nötig.
Auto-Tagging ohne Künstliche Intelligenz
Ein klassischer, aber oft vergessener Workflow im Digital Asset Management ermöglicht das automatische Taggen sämtlicher Produktbilder und -videos, indem standardisierte Dateinamen oder XMP-Metadaten verwendet werden, die in den Dateiheadern gespeichert werden. Hierfür definiert man eine Namenskonvention, erweitert diese um eine einmalige Produkt-Referenznummer (SKU) und einen vorangestellten Identifier und erhält so einen Produktcode. Zum Beispiel:
- JetX3467-with-operator_PID12384689234.jpg
- PID12384689234_X3467 movie.mov
- WeldingJetX3467 leaflet-PID12384689234-new-june2018.pdf
All diese kleinen Aufwendungen werden durch grosse Kosteneinsparungen wett gemacht, welche sich durch einen höheren Grad an Automatisierung ergeben (wo Ihnen KI zumindest heute noch in Sachen Produkterkennung wenig hilft).
Unabhängig davon, ob man sich hierbei an strikte Richtlinien hält oder nur dafür sorgt, dass die Produkt-ID mit den nötigen Trennzeichen hinzugefügt wird (wie im Beispiel) spielt es keine Rolle, ob das verwendete Content System die Information automatisch aus dem Dateinamen oder aus einem speziell definierten XMP-Feld extrahiert und dann mit der entsprechenden Produktliste vergleicht.
Idealerweise definiert diese Liste auch Produktmarke, -kategorie, Verwendungsbereich, Lebenszykluskategorie, Marktverfügbarkeit, etc., die alle auch als Master-Daten aus einem PIM oder ERP stammen können. Danach können die Benutzer vertikal oder nach Produktmarke suchen und so sämtliche verwandte Bilder, Videos und andere Ressourcen finden — alles basierend auf Auto-Tagging-Content und einem einzelnen Produkt-Identifier.
Falls Ihr System multi-dimensionale Metadaten unterstützt, kann das Hinzufügen eines einzelnen “Produkt-ID” Tags eine grosse Anzahl relevanter Produktattribute mit einem Bild oder Video verbinden.
Mittels semantischer Verknüpfungen können neu hinzugefügte Inhalte auch einfacher mit verwandten Daten verbunden werden, welche bereits in Ihrem Content-System abgelegt sind.
Hierfür sind standardisierte Produktions-Workflows nötig, die sicherstellen, dass die Produkt-ID in jeder Datei mit spezifischem Produkt-Content enthalten ist. Aber sobald mehr als nur eine Handvoll Produkte verwaltet wird, stehen diese Informationen ohnehin zur Verfügung. Verglichen mit anderen Standards unerheblich, die greifen, wenn die Produkte tatsächlich hergestellt werden, ist diese Standardisierung unerheblich.
All diese kleinen Aufwendungen werden durch grosse Kosteneinsparungen wett gemacht, welche sich durch einen höheren Grad an Automatisierung ergeben (wo Ihnen KI zumindest heute noch in Sachen Produkterkennung wenig hilft).
Erweiterte Content-Workflows anstossen
Das automatische Tagging von Content ist nicht immer das endgültige Ziel. Es kann Teil einer Workflow-Chain sein und weitere Arbeitsschritte auslösen, die eine Menge Zeit und Geld sparen können und die man vielleicht erst bei genauerem Hinsehen erkennt.
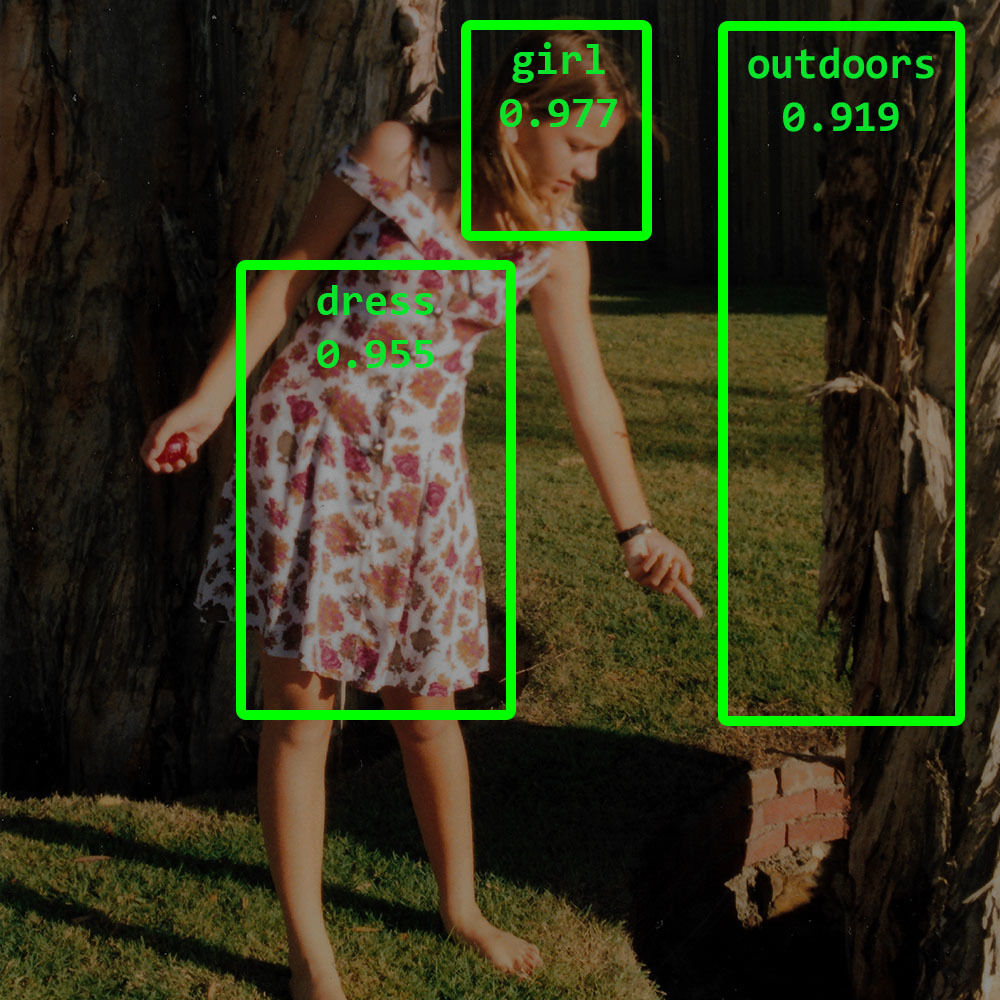
Wurde der Content beispielsweise mit dem Tag “Personen” versehen, will man möglicherweise manuell überprüfen, ob und für welche Verwendungsarten eine ausdrückliche Genehmigung der abgebildeten Personen nötig ist. Ohne eine solche ausdrückliche Genehmigung und Aufklärung über den Verwendungszweck für die Nutzer, drohen hohe Strafen im Rahmen der DSGVO und anderer Regelungen, die wir kürzlich hier im Blog unter dem Titel “Digital Asset Management und die Datenschutz-Grundverordnung der EU (DSGVO)” besprochen haben.
Das Schlüsselwort “Personen” könnte aber auch eine Überprüfung auf die Einhaltung von Sicherheitsvorschriften anstossen: Tragen alle Personen auf der Baustelle einen Helm? Hat die Person an der Bohrmaschine eine Sicherheitsbrille auf? Falls nicht, sind die Bilder unter Umständen nicht zur Weitergabe geeignet, ohne dass Sie Ihren Ruf riskieren.
In Bildern oder Videos von Veranstaltungen könnten im Hintergrund Logos von Mitbewerbern zu sehen sein, die durch Auto-Tagging-Anbieter erkannt werden können. Diese Bilder sollten nicht unbedingt weitergeben, sondern vor der Bereitstellung in Ihren Content-Portalen oder der Veröffentlichung auf Ihren Websites aussortiert werden.
Inhalte auf Basis negativer Begriffe aussortieren

Möglicherweise soll auch eine Liste mit Tags erstellt werden, die beim Auffinden einen Alarm auslösen. Handelt es sich beispielsweise um ein petrochemisches Unternehmen und alle Bilder der Raffinerie bei Sonnenuntergang werden automatisch mit dem Tag “Umweltverschmutzung” versehen, ist es vermutlich nicht sinnvoll, diese Bilder zu veröffentlichen.
Auf keinen Fall sollte der Begriff “Umweltverschmutzung” den Benutzern direkt neben dem Bild angezeigt werden. Das führt zu der grösseren Frage, wie das verwendete Content System automatische Tags speichert und wie, sofern es die Tags weiterhin finden kann, diese vor den Benutzern verborgen werden können. Und selbstverständlich geht es auch darum, ob die automatischen Tags ggf. entfernt werden können.
Vermutlich existieren weitere Szenarien, in denen bei bestimmten “negativen Begriffen” eine manuelle Überprüfung des Contents durch einen Experten angestossen werden sollte.
Testfahrt für Auto-Tagging
Sobald die Informationsarchitektur definiert ist, wird man verschiedene Auto-Tagging-Dienste wie Clarifai, Google Vision API, Amazon Rekognition, Imagga or Azure Cognitive Services anhand einer repräsentativen Gruppe von Bildern oder Videos testen wollen. Hierfür kann man innerhalb der kostenlosen Kontingente ein paar Testläufe durchführen, um die grundsätzlichen Möglichkeiten besser zu verstehen. Zudem beginnt man darüber nachzudenken, welche Tags eventuell weitere Verarbeitungsschritte anstossen.
Kein menschlicher Review? Immer als auto-tagged deklarieren
Je nach verwendeter Informationsarchitektur können einige Content-Typen (z.B. Archivbilder) problemlos automatisch getaggt werden, weil a) das immer noch besser ist, als Bilder ohne Tags gar nicht zu finden, b) das Risiko ziemlich gering ist, dass etwas wirklich schiefgeht und c) die Kostenersparnis riesig ist, wenn nicht sämtlicher Content manuell bearbeitet werden muss.
Sobald Inhalte ohne menschliche Überprüfung automatisch getaggt werden, sollte der Content allerdings transparent als “automatisch getaggt” markiert werden. Ansonsten sind die Benutzer möglicherweise verwirrt, wenn etwas falsch bezeichnet ist, obwohl es sich klar um etwas anderes handelt (oder anders genannt werden sollte). Tut man das nicht, kann sich das negativ auf die Glaubwürdigkeit kuratierter Content-Sammlungen auswirken.
Blick in die Zukunft: Change Management einplanen
Überlegt man, künstliche Intelligenz (KI) für das Tagging von Content mit Metadaten zu verwenden, sollte hierfür eine langfristige Perspektive entwickelt werden.
Die KI-Technologie macht schnell grosse Fortschritte. Was heute noch mit einem niedrigen Confidence Score getaggt wird, wird in Zukunft wahrscheinlich korrekt erkannt.
Die KI-Technologie macht schnell grosse Fortschritte. Was heute noch mit einem niedrigen Confidence Score getaggt wird, wird in Zukunft wahrscheinlich korrekt erkannt. Daher sollte man seine Informationsarchitektur schon jetzt darauf vorbereiten, die Tags in einem Jahr erneut zu erstellen, indem alle oder ausgewählte Inhalte erneut an den Tagging Service übergeben werden. Hierfür muss zumindest gespeichert werden, wann das letzte Auto-Tagging durchgeführt wurde und welche Tagging Services verwendet wurden.
Das Change Management muss darauf vorbereitet sein, dass sich die Ergebnisse im Laufe der Zeit verändern können.
Trainieren Sie Ihre Maschine (Machine Learning)
Eine der grössten Quellen zukünftiger Verbesserungen beim Auto-Tagging ist das, was Maschinen von menschlichen Benutzern lernen. Die meisten Tagging Services bieten Kunden die Möglichkeit, Tagging-Modelle zu trainieren, indem Content an den Dienst geschickt wird und die zurückgegebenen Tags manuell definiert oder bei Bedarf hinzugefügt werden können. Durch Analyse des Contents und der manuell hinzugefügten oder entfernten Tags können die Dienste ihre Machine Learning (ML)-Algorithmen verwenden, um zukünftige Ergebnisse zu verbessern.
Je besser ein solches “Feedback” in das eigene Content System integriert ist, desto geringer der Aufwand für das Training des Tagging Services und desto präziser das Tagging des eigenen Contents. (Allerdings sollte man beachten, dass ML auch sehr seltsame Ergebnisse liefern kann und bei weitem nicht ideal ist.)
Immer Kleingedrucktes lesen
Bei der Verwendung von Auto-Tagging-Diensten oder deren Training sollte man auf jeden Fall auf das Kleingedruckte im Vertrag achten. Eventuell vergibt man das Recht, Teile des Contents weiter zu verwenden. Kritisches geistiges Eigentum wie beispielsweise neue Produktvorlagen oder Investor-Informationen können auf diese Weise ungewollt exponiert werden.
Noch einmal: Mit einer vernünftigen Informationsarchitektur für das Digital Asset Management oder die Content Management-Initiative von Anfang an, lässt sich verhindern, dass diese Content-Typen überhaupt an einen Auto-Tagging-Service übergeben werden müssen.
Sehen sie doppelt? Duplikate finden
Manche Auto-Tagging-Anbieter stellen als Nebenprodukt ausserdem Technologien zum Finden und Gruppieren anhand visueller Muster zur Verfügung, wodurch doppelter Content leichter gefunden werden kannn. Meist reichen Dateinamen oder Prüfsummenvergleiche nicht aus. Der gleiche Bildinhalt kann beispielsweise in verschiedenen Dateiformaten wie TIFF oder JPEG vorliegen, was verschiedene Dateinamen und Prüfsummen nach sich zieht.
Dennoch können selbst Dienste ohne diese Fähigkeiten eine Hilfe beim Auffinden von Duplikaten sein, indem einfach die Tags verglichen werden: Bei Dateien, die automatisch die gleichen Tags und Confidence Scores erhalten haben, handelt es sich möglicherweise um Duplikate, oder zumindest um sehr ähnlichen Content. Das kann beim manuellen Batch Editing oder bei der Zusammenstellung der besten Bilder für eine kuratierte Sammlung helfen.
Videos und Dokumente automatisch taggen
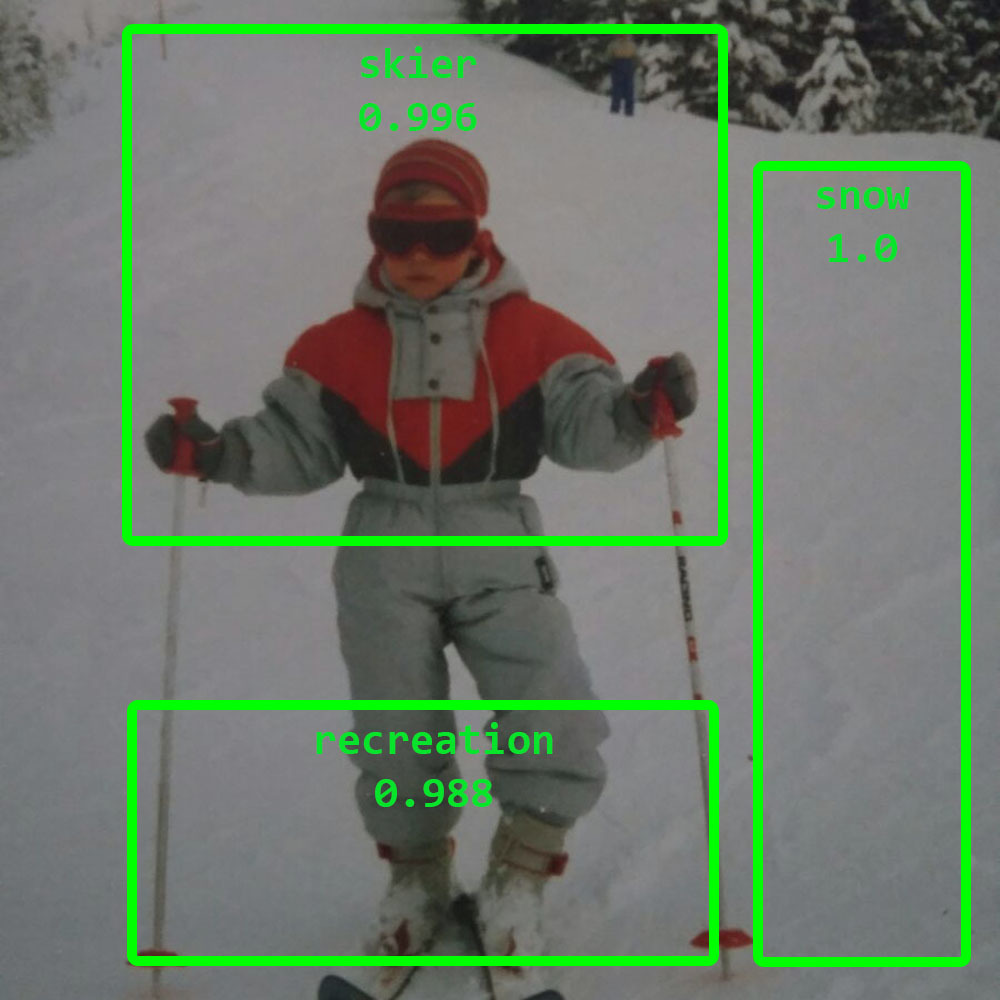
Videos werden immer beliebter. Da es sich um eine Folge von Bildern handelt, ist es schwieriger, Videos korrekt zu taggen.
Sind Videos wichtig, so sollte man sicherstellen, dass ein Tagging Service verwendet wird, der Szenenwechsel erkennen kann und nicht nur alle fünf Sekunden ein Standbild analysiert. Das eigene Content Management-System erhält so die Möglichkeit, jede vom Auto-Tagging Service identifizierte Szene zum Setzen von Markierungen in der Timeline zu verwenden. Diese können Benutzern dann als Sprungmarken (“cue points”) für die Navigation im Video dienen.
Dokumente werden von vielen Auto-Tagging Services wie Clarifai gar nicht verarbeitet. Grössere Player wie Google bieten hierfür jedoch dedizierte Dienste, ausserdem können die meisten Content Management-Systeme heutzutage einen Volltext-Index für die Rückgabe relevanter Suchergebnisse aus Dokumenten erstellen.
Häufig sollen diese Dokumente aber nicht nur durchsucht, sondern automatisch gemäss der unternehmenseigenen Taxonomie getaggt werden. Hierfür benötigt das Content System eine Form der Intelligenz, um beispielsweise einen zwanzigseitigen Prospekt nicht mit allen Begriffen der Taxonomie zu taggen, sondern nur die wirklich relevanten Tags zu verwenden.
Keine Angst vor künstlicher Intelligenz
Die meisten Bibliothekare und Taxonomisten mit denen ich geredet habe, verurteilen automatisch getaggten Content immer noch als “nicht relevant oder inakkurat” getaggt und sagen voraus, dass KI “einen guten menschlichen Taxonomisten niemals ersetzen wird.”
Es ist eine Tatsache, dass die Menge an Content weiterhin so stark ansteigen wird, so dass Menschen alleine nicht mehr in der Lage sind, diese zu bestmöglich zu verarbeiten.
Obwohl ich die Motivation dieser Aussagen verstehe, ist es eine Tatsache, dass die Menge an Content in naher Zukunft so sehr ansteigen wird, dass sie von Menschen nicht mehr bestmöglich verarbeitet werden kann.
Dabei benötigt nicht jeder Content-Typ einen vollständigen Satz an Metadaten. Auch die Genauigkeit beim Tagging ist nicht immer das Wichtigste. Das gilt besonders, wenn der Content ansonsten nicht rechtzeitig oder möglicherweise gar nicht getaggt wird.
Ausserdem wächst die Leistungsfähigkeit künstlicher Intelligenz rapide. Man denke nur an selbstfahrende Autos, Assistenzsysteme, Sicherheitsüberwachung, usw., die alle Bilderkennungsverfahren als Teil einer grösseren Lösung verwenden. Diese Bereiche angewandter KI treiben die Innovation viel schneller voran als die Content Management-Industrie.
Die so wichtige menschliche Note
Die Meinung vieler Taxonomisten ignoriert ausserdem eine grosse Chance: Durch automatisches Tagging können Fachexperten sich wieder auf die Dinge konzentrieren, die sie besser können als Maschinen. Zum Beispiel:

-
- Den korrekten Kontext und spezifische Details bereitstellen, die Auto-Tagging Services nur schwer oder gar nicht erkennen (historischer oder unternehmensspezifischer Kontext, implizite Nachrichten, Stimmungen und Emotionen)
- Ausgewählten automatisch getaggten Content zur Verbesserung der Genauigkeit überprüfen, falsche Ergebnisse entfernen und fehlende Tags ergänzen (was oftmals schneller ist, als das Tagging erneut durchzuführen)
- Auto-Tagging-Modelle trainieren, um bestimmten Content nach unternehmenseigenen Vokabularien und Bedürfnissen genauer zu taggen.
- Von Benutzern oder Auto-Tagging Services vorgeschlagene Tags überprüfen und genehmigen, multidimensionale Metadaten kuratieren und pflegen, semantische Beziehungen definieren.
- Das Fundament verbessern, mit dem alles beginnen sollte: Die eigene Informationsarchitektur, die exakt auf die sich schneller als je zuvor ändernden Bedürfnisse eines Unternehmens zugeschnitten ist.
Werden Auto-Tagging Services in Content Systemen eingesetzt, bieten sie bereits heute viele Vorteile (und in Zukunft noch deutlich mehr!) Es liegt an uns Menschen, diese Dienste sinnvoll einzusetzen und uns wieder auf die Dinge zu konzentrieren, die wir seit Langem am besten können: Die Lösung komplexer, kontextreicher und nicht-repetitiver Probleme mit viel Kontext.
