By Picturepark Communication Team • Jan 17, 2014
How can you move beyond using only narrative descriptions for your digital assets? Digital asset management consultant, Ralph Windsor, explains in this four-part guest post series on the advantages of structured metadata.
Further reading: Part 1 | Part 2 | Part 3 | Part 4
One topic you will rarely find people in Digital Asset Management circles arguing about the need for is highly optimised asset findability: making assets as simple as possible to locate using the search tools that a given DAM systems might include. To achieve this goal, you require relevant metadata that will produce non-misleading and accurate results based on the characteristics of the asset file.
Understanding Fundamental Differences between Types of Metadata
The nature of digital asset metadata typically subdivides into two major routes: free-text narrative and structured information. The former is fields like descriptions, captions, titles etc. This is easy for non-experts to grasp and can be highly descriptive because it is natural language in form and can therefore be entered and understood by anyone who is literate.
There are downsides to this method, though. The two biggest are:
- Effort
- Ambiguity
Since someone has to write copy about each asset, the cataloguer needs to review it and then come up with a description. The effort required might increase considerably for some time-based assets like video, and even for images, there is a lot of potential to get it wrong.
On DAM News, I wrote an article about effective narrative based asset cataloguing. You can see from this article that, although conceptually simple, it does require some thought and practice to do well. For small and select groups of high quality assets, this can be worthwhile. If you have many thousands of assets, however, and limited time or human resources available to assist with the task, a full narrative description written individually for each asset may be a luxury that is hard to justify for every asset in the entire collection.
Whatever language you are cataloguing assets in, narrative terms like colours, size adjectives and even locations can be misinterpreted when taken out of context. Due to the nature of the free-text search, this will almost inevitably happen when the user enters some arbitrary keywords.
I should emphasise that narrative descriptions are still a highly effective method of cataloguing assets. But the task is a skilled one that can be costly to carry out at high volumes.
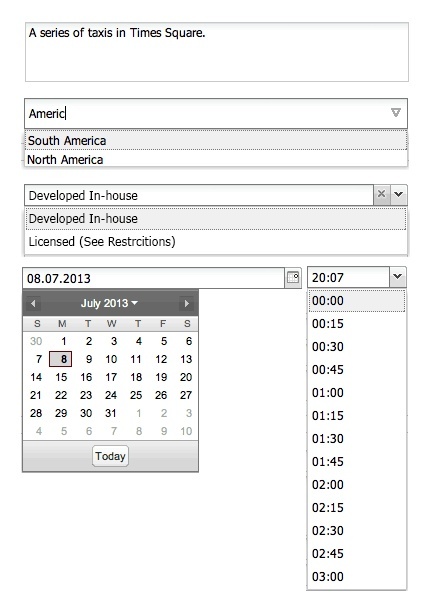
Free-text narratives are easy for users to understand but they are not always the most efficient when it comes to metadata integrity or “findability.” Structured fields, such as drop-downs, type-ahead controlled vocabulary fields and date pickers can make metadata editing and searching easier.
Using a structured method can add clarification and context to existing narratives. For those assets that have no prior metadata applied at all, structured metadata can provide some basic descriptions that significantly increase the likelihood of assets getting found in searches, even where no other descriptive metadata has been provided.
Structured metadata enables a more controlled input for both searches and cataloguing. If the two are in alignment, the potential to avoid null results is further increased because both cataloguer and searcher are using common sets of terms. This is what is referred to as a controlled vocabulary. When you are cataloguing, you are presented only with terms that are suitable for use with the assets being catalogued. When searching, you can see more easily those that will produce results, and quickly get an idea about the overall topics and themes of the assets held within the library.

In this image, a controlled vocabulary has been assigned to a metadata field. Allowable values are indicated by type-ahead functionality.
Common Structured Metadata In Digital Asset Management
Having decided that augmenting your asset metadata strategy with structured techniques is a good idea, how do you decide what to offer to your DAM users?
A lot depends on the DAM system you are using and what capabilities it can offer. Essentially you are designing a user interface for two key groups of users: cataloguers and searchers. The two groups are by no means mutually exclusive—cataloguers will be searching too. But in terms of the task being carried out, they should be treated independently.
In the next article in this series, I will describe some common options for cataloguing and search respectively.